2.3 Database Architecture and the Django Framework
Figure 2.3 illustrates the complete transformation and architecture of the DttG database: from the initial single-sheet ‘master’ spreadsheet (top), to its reorganisation into six interrelated tables (middle), and finally to the construction of a web-based application using the Django framework (bottom). While the relational database already enabled structured, SQL-based querying, this did not satisfy the project’s aim of making the data accessible and usable for a broad art-historical audience. To achieve this, we developed a web interface that allows users to browse, query, and export data subsets without requiring any programming knowledge or technical expertise.
Django is an open-source, high-level Python web framework designed to support the creation of complex, database-driven websites.1 It is widely used for its clarity, stability, scalability, and ease of use, and has been adopted across both academic and commercial contexts, including large-scale platforms such as Instagram and The Washington Post. This widespread use ensures that Django is actively maintained by an active developer community and benefits from regular updates, reducing the risk of obsolescence. This long-term support was a key factor in our decision to adopt Django, particularly given the challenges of sustaining digital infrastructure in humanities research contexts, where long-term funding and technical support can be limited.
For the DttG project, the most relevant components within Django are the models and templates. The models from the foundation of the application and correspond directly to the six interlinked tables described before–Data, Artworks, Artists, Museums, Cities, and Colours. Each model defines the structure of its table: which fields are required, what type of data each field accepts (text, numbers, dates etc.), and how the models relate to one another. For example, the Artwork model specifies that every painting must at least have a unique ID, a title, and a reference to an artist, with additional optional fields.
On top of this data structure, Django uses templates to define how the information is displayed on the website. Templates are written in HTML (Hypertext Markup Language), the standard language for web content, and serve as reusable page layouts. Rather than designing a separate webpage for each painting in the database, we created a single template that specifies where the image, title, artist, and technical data should appear. Django then automatically fills this layout with the relevant data from the database, generating an individual webpage for each record. This approach allows for the consistent display of hundreds of entries without requiring repetitive web design work.
Once the system was capable of dynamically generating these pages, the next step was to enable users to search and filter the database interactively according to their research questions. Two levels of search functionality were developed. The simple search allows users to find works based on straightforward criteria, such as artist name, date, or number of ground layers. The advanced search builds on this by allowing multiple parameters to be combined at once. Both search modes translate the logic of SQL queries into intuitive dropdown menus and checkboxes, allowing users to perform complex queries without needing to learn SQL syntax.
While Django forms the technical backbone of the database, accessibility for non-technical researchers was the guiding priority. For this reason, data entry remains possible through structured Excel templates that mirror the database schema, with one spreadsheet corresponding to each relational table. A custom Python conversion script parses these spreadsheets and populates or updates the database. This conversion step acts as an important quality-control step. If, for example, a researcher attempts to input an artwork that references an artist not found in the Artists table, or uses a colour code not recognised in the Colours table, the script will reject the entry and return an error. In this way, we preserve the accessibility and familiarity of Excel for external researchers, while retaining the structural rigor of the database to enforce internal consistency.
In addition to these custom features, the application benefits from a number of Django’s built-in functions that reduce development times. The framework automatically generates an administrative interface, which allows project members to log in securely and assign them rights to add, edit, and review entries. This eliminated the need to build data-entry forms from scratch and ensured that the database could be maintained with minimal overhead. Django also handles other commonly required backend features such as user authentication, pagination of search results, and the efficient underlying management of queries and relationships between tables.
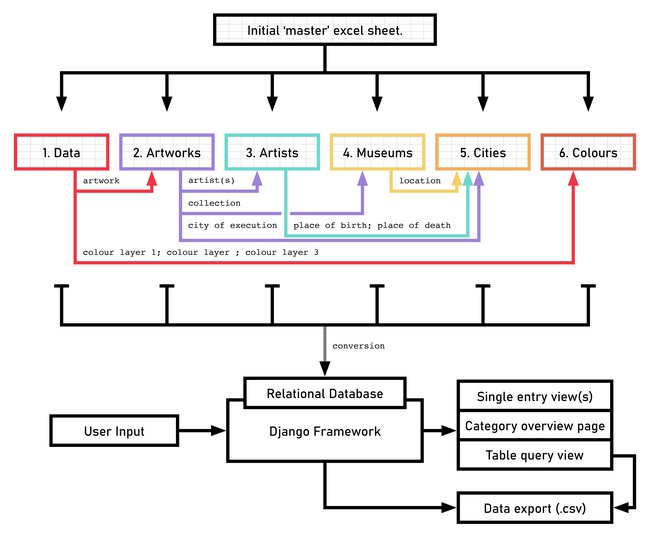
Figure 2.3 Overview of the data transformation workflow for the DttG database.
From top to bottom: the initial single-sheet master spreadsheet; its decomposition into six interrelated tables; and its implementation as a relational database within the Django web framework. The diagram illustrates how the structured backend supports web-based browsing, querying, and data export through the DttG application interface.
Notes
1 “Django,” Django Project, accessed October 10, 2025, https://www.djangoproject.com/