2.2 Principles of Relational Database Design and Structured Query Language (SQL)
Unlike spreadsheets, which store data in a single grid, a relational database organises information into multiple interrelated tables, each with a defined purpose and structure. A central principle in this design is data normalisation: the practice of grouping related data logically and storing each distinct piece of information only once. In the context of the Down to the Ground (DttG) database, for example, all information about artists is stored in a dedicated Artist table, while each painting has its own record in a separate Artwork table. Rather than duplicating an artist’s name and biographical data for every painting, the Artwork table simply references the corresponding artist through a unique identifier. This approach minimises the risk of inconsistency, and if a correction is needed (such as updating the spelling of a name) it can be made once in the Artist table and will propagate automatically across all linked records. Figure 2.1 shows the relational database structure after reformatting the database.
Although database tables may resemble spreadsheets in their layout of rows and columns, they differ crucially in that each field is defined to accept a specified type of data and follow certain rules. These may include the data type (text, number, date etc.), whether the field can be left empty, or whether its value must match a reference elsewhere in the system. The database enforces these rules automatically, rejecting incompatible entries. For example, a field designed to store a year will reject alphabetic input, and an artwork record cannot be saved unless it references a valid artist already present in the Artist table. This built-in validation ensures that data remains internally consistent and free from many of the small errors that accumulate in free-form spreadsheets.
Relationships between tables are maintained using keys. Each table includes a primary key: a unique identifier assigned to each record (for instance, an artwork id). Other tables refer to these identifiers using foreign keys, establishing a logical link between related records. In practice, this means that a painting entry in the Artwork table points to its associated artist(s) through the artist id, ensuring that only valid, existing artists can be linked. This mechanism enforces referential integrity, preventing orphaned records or contradictory associations.
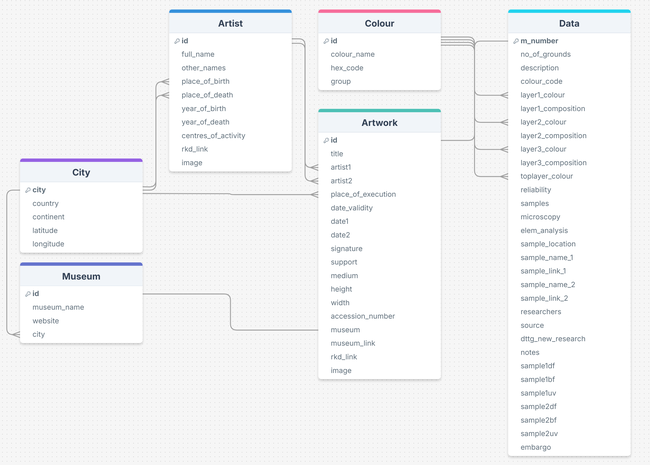
Figure 2.1 Relational structure of the Down to the Ground (DttG) database.
Diagram showing the six interconnected tables—Artwork, Artist, Museum, Cities, Colour, and Data—and their respective fields. The schema illustrates how information is organised and linked through unique identifiers to maintain consistency across records.
The full advantage of this structured architecture becomes clear when paired with Structured Query Language (SQL), the standard language used to retrieve, combine, and analyse information in relational databases. SQL allows researchers to formulate complex, multi-criteria questions in a precise and reproducible way. For example, a researcher can ask to retrieve all Utrecht paintings executed between 1600 and 1625 that use a red ground with a confirmed material analysis. Such a query draws together information from multiple tables–metadata stored in the Artwork table, geographic data from the Artist table, and data on grounds from the Data table–by filtering, joining, and comparing records according to defined relationships. What would require manual sorting and cross-referencing in Excel can be performed by the database in seconds. SQL thus turns the dataset into an interactive research tool rather than a static repository. Figure 2.2 provides an example of such a query.

Figure 2.2 Example of a Structured Query Language (SQL) command used within the DttG database. This query retrieves all paintings executed in Utrecht between 1600 and 1625 that use a red ground confirmed through material analysis. It demonstrates how structured queries allow complex, reproducible filtering across multiple related tables.